Havasu supports spatial filter based data skipping. This feature allows user to skip reading data files that don’t contain data that satisfy the spatial filter. Consider the following spatial range query:
Havasu will skip reading data files that don’t contain data that satisfy the spatial filter. This feature is very useful when the table contains a large amount of data and the spatial filter is very selective. For example, if the table contains 1TB of data and the spatial filter will only select 1% of the data, Ideally Havasu will only read ~ 10GB of data to answer the query.
How Spatial Filter Push-down Works
Havasu collects and records the spatial statistics of data files when writing data to the table. The spatial statistics includes the minimum bounding rectangle (MBR) of the geometries in the data file. When a spatial query is issued, Havasu will first check the MBR of the geometries in the data file against the spatial filter. If the MBR doesn’t intersect with the spatial filter, Havasu will skip reading the data file.
The following figure shows how spatial filter push-down works. The MBRs of each data file were maintained in Havasu metadata for pruning data files. The query window shown as the red rectangle only overlaps with the bounding box of datafile-2.parquet and datafile-4.parquet, so Havasu can safely skip scanning datafile-1.parquet and datafile-3.parquet, reducing the IO cost and answer the query faster.
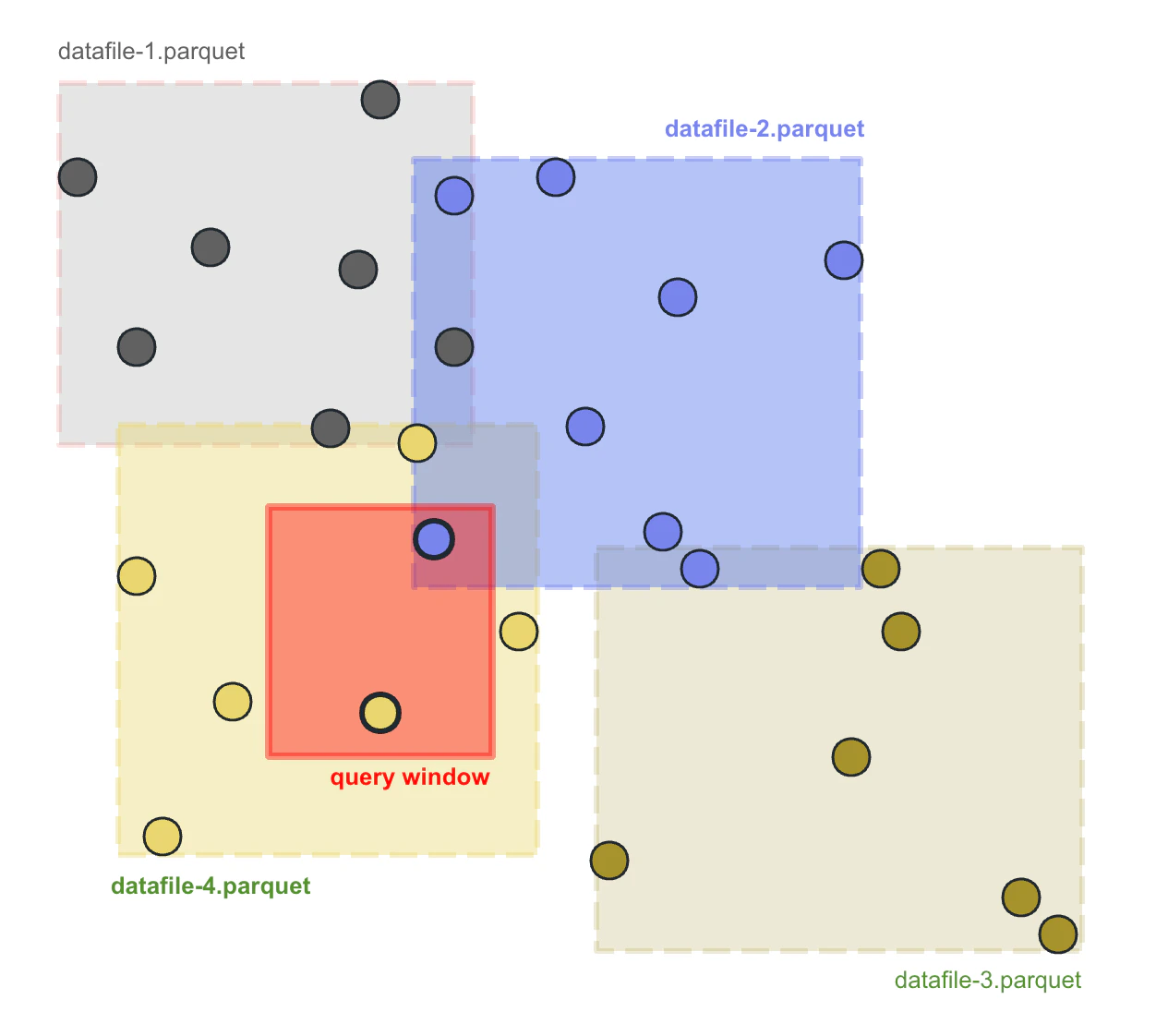 Spatial filter push down works best when the spatial data near to each other were stored in the same file. This can be achieved by applying a proper partitioning to the table so that the data near to each other will be stored in the same partition, or sort the table to cluster the data by the geometry column.
Spatial filter push down works best when the spatial data near to each other were stored in the same file. This can be achieved by applying a proper partitioning to the table so that the data near to each other will be stored in the same partition, or sort the table to cluster the data by the geometry column.
CREATE SPATIAL INDEX statement
Havasu provides a syntax CREATE SPATIAL INDEX for rewriting the table to sort the records by geometry column:
This statement will rewrite the data files of the table and cluster the data by the geometry column. Currently, Havasu only supports the hilbert index strategy. hilbert will sort the data by the by the Hilbert index of specified geometry field. Hilbert index is based on a space filling curve called Hilbert curve, which is very efficient at sorting geospatial data by spatial proximity. You can specify the precision of the hilbert curve using the precision parameter. The precision parameter is the number of bits used to represent the Hilbert index. The higher the precision, the more accurate the sorting will be.
hilbert only works for WGS84 coordinates, the input geom should be bounded within [-180, 180] and [-90, 90].
wherobots.db.test_table by the geometry column geom:
CREATE SPATIAL INDEX FOR is actually a syntax sugar for calling rewrite_data_files procedure:
Users can apply any options supported by rewrite_data_files procedure to CREATE SPATIAL INDEX FOR statement using the OPTIONS clause. For example, we can set the target file size to 10MB:
This is equivalent to
Users can also specify a condition to filter the data to be rewritten. For example, we can rewrite the data files of the table containing data with state = 'CA':
This is equivalent to
Usually, users don’t need to specify the target-file-count option, as the CREATE SPATIAL INDEX statement will automatically determine the size of output data files based on the size of the table to balance the file size and the number of data files.
If the default behavior of CREATE SPATIAL INDEX is not desirable, users can specify the following options to control the number of data files:
target-file-count: The number of output data files. This option is useful when you want to rewrite the table to an expected number of data files. The exact number of data files may be different from the expected number due to various factors such as compression, heuristics for avoiding too large data files, etc.
Other Ways to Index Spatial Data
Except for the CREATE SPATIAL INDEX FOR statement, there are many other ways to index geospatial data in Havasu.
If the data you are working with has at least one columns that are closely related to the spatial property, it is usually a good idea to partition the table using that column. For example, if you are working with a table containing census data, and the data has a state column indicating the state ID of the data, you can partition the table by state:
The state partition works well for both regular queries with filters such as state = 'some_state' and spatial queries with filters such as ST_Intersects(geom, <query_window>. For the former, Havasu uses the hidden partitioning feature of Apache Iceberg will skip reading data files according to the partition info, and for the latter, Havasu will skip reading data files using the spatial statistics of data files.
Partitioning by spatial proximity
If your dataset does not have a field to directly partition by, you can partition the dataset by the S2 cell ID of the geometry. This requires selecting a proper S2 resolution level suited for your dataset.
The data inserted into the table should have the s2 column set to the S2 cell ID of the geometry:
Though the table was partitioned using S2, we don’t need to add a predicate for the s2 partitioning column to achieve
data skipping. Havasu will use the spatial statistics of data files and automatically skip reading data files that don’t contain data that satisfy the spatial filter.
Sorting by GeoHash
We can manually sort the table by ST_GeoHash(<geometry_column>, <precision>) to cluster the data by spatial proximity:
It is generally recommended to use CREATE SPATIAL INDEX FOR for sorting the table over manually sorting the table. CREATE SPATIAL INDEX FOR will use the Hilbert curve to sort the table, which is more efficient than sorting by GeoHash.