Wherobots Job Submission Guide¶
Overview: Understanding Wherobots Job Submission¶
The Wherobots Job Submission functionality enables users to efficiently configure, initiate, and monitor computational tasks. Here's a summary of its capabilities:
- Easily set up and initiate computational tasks using the platform's intuitive interface.
- Configurable task parameters including runtime environments, driver settings, and advanced configurations.
- Real-time monitoring of job status and execution details.
This feature provides a seamless approach to managing and executing jobs on the Wherobots platform.
Job Dashboard Access¶
- Accessible via the "Jobs" tab on the left navigation pane.
- Provides a list of all created jobs and their associated management options.
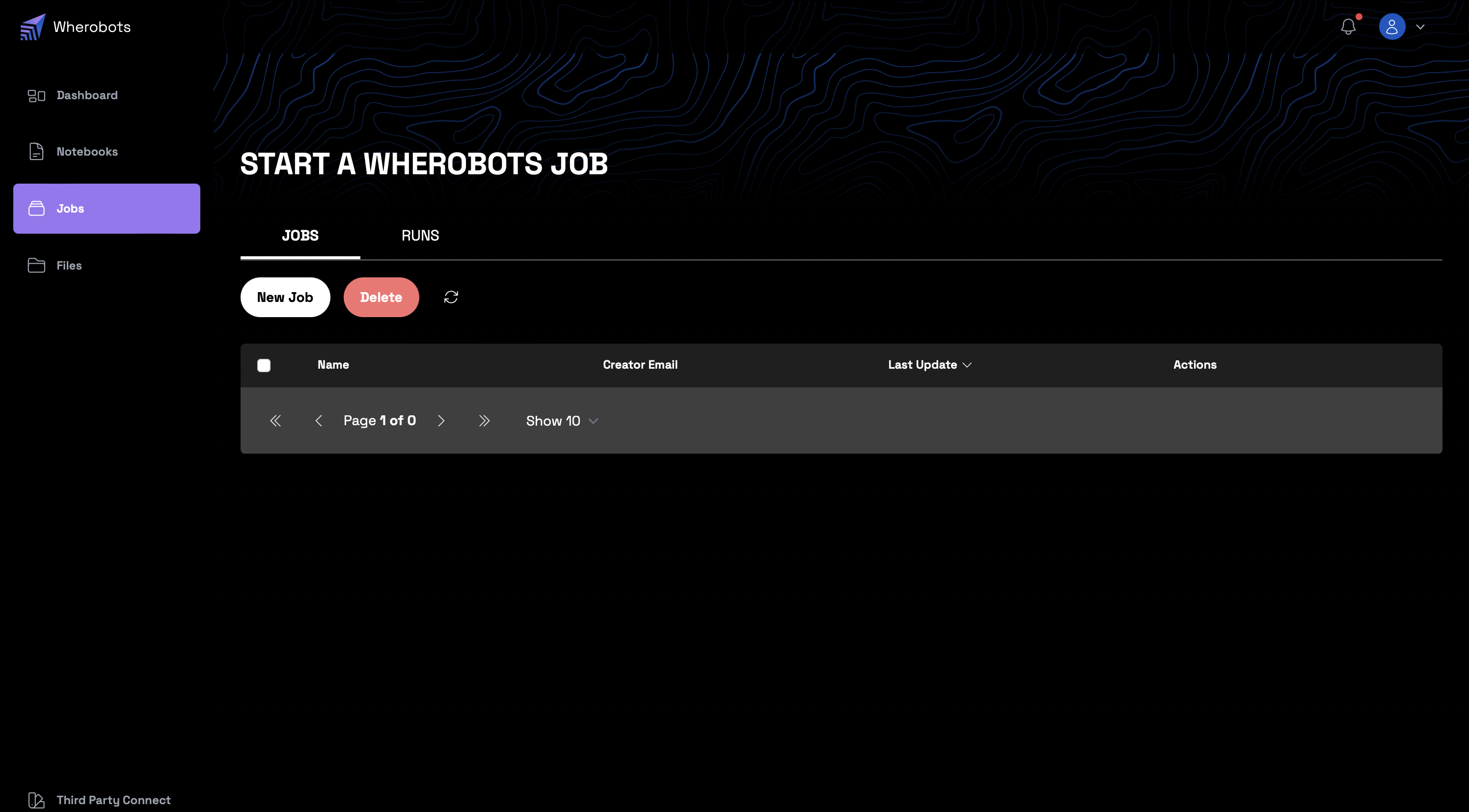
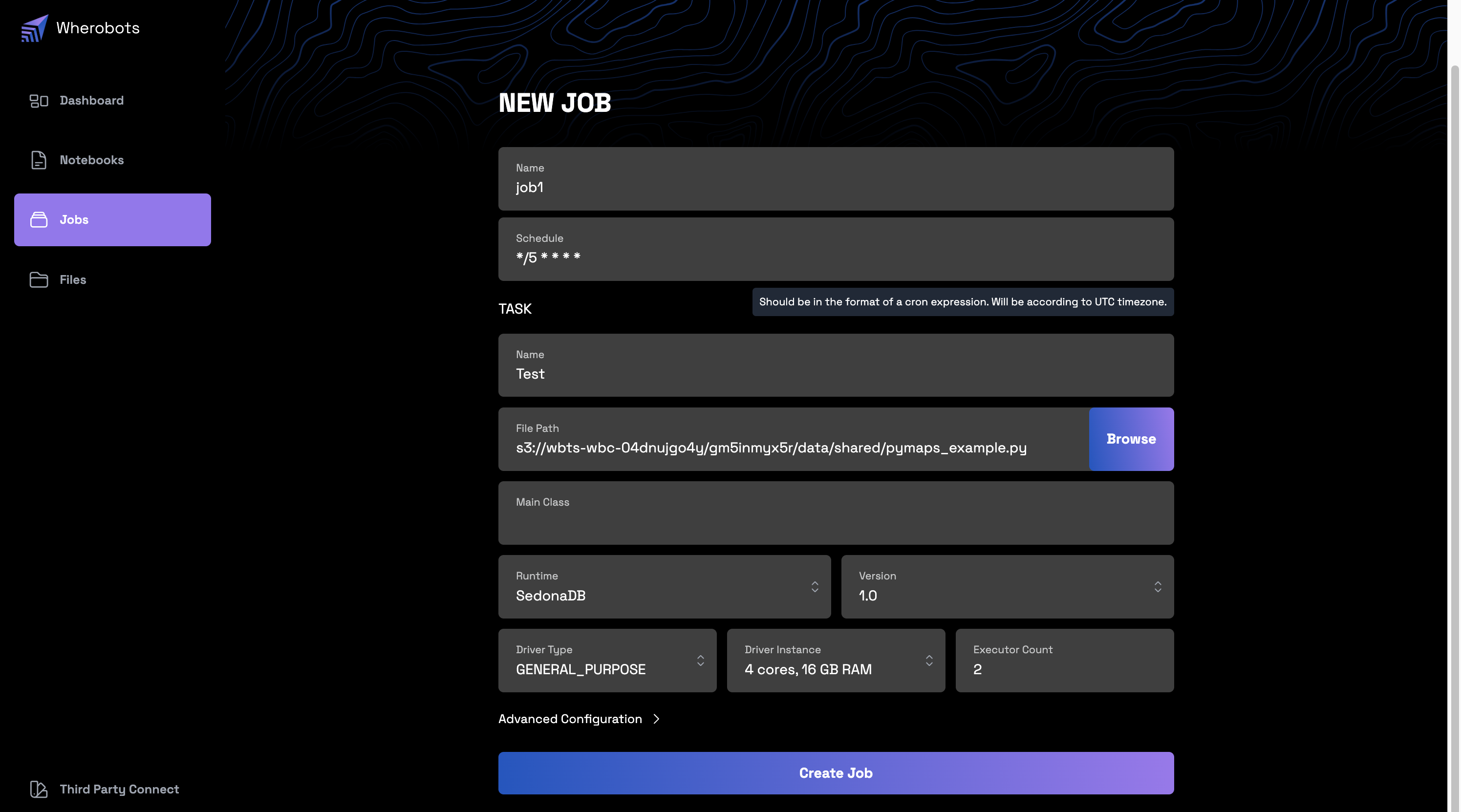
Creating a New Job¶
- To initiate a new job, click the "New Job" button. Here's a summary of the configurations available:
| Configuration | Description | |
|---|---|---|
| Name | Unique name for your job. | |
| Schedule | Use cron format to set up a run schedule. Generate cron. (UTC timezone based) | |
| Tasks | ||
| Name | Name for the task. | |
| File Path | Browse to select the desired file or script. | |
| Main Class | For JAR files, specify the main class for execution. | |
| Runtime & Version | Select the runtime environment and version. | |
| Driver Configuration | Define driver type, instance, and executor count. | |
| Advanced Configuration | ||
| Executor Defaults | If unspecified: Type and Instance same as Driver, Disk Size: 20GB each. | |
| Optional Parameters | Set parameters like disk size, timeout, retries, environment variables, arguments, Spark configurations, etc. | |
| Libraries | Attach necessary libraries. | |
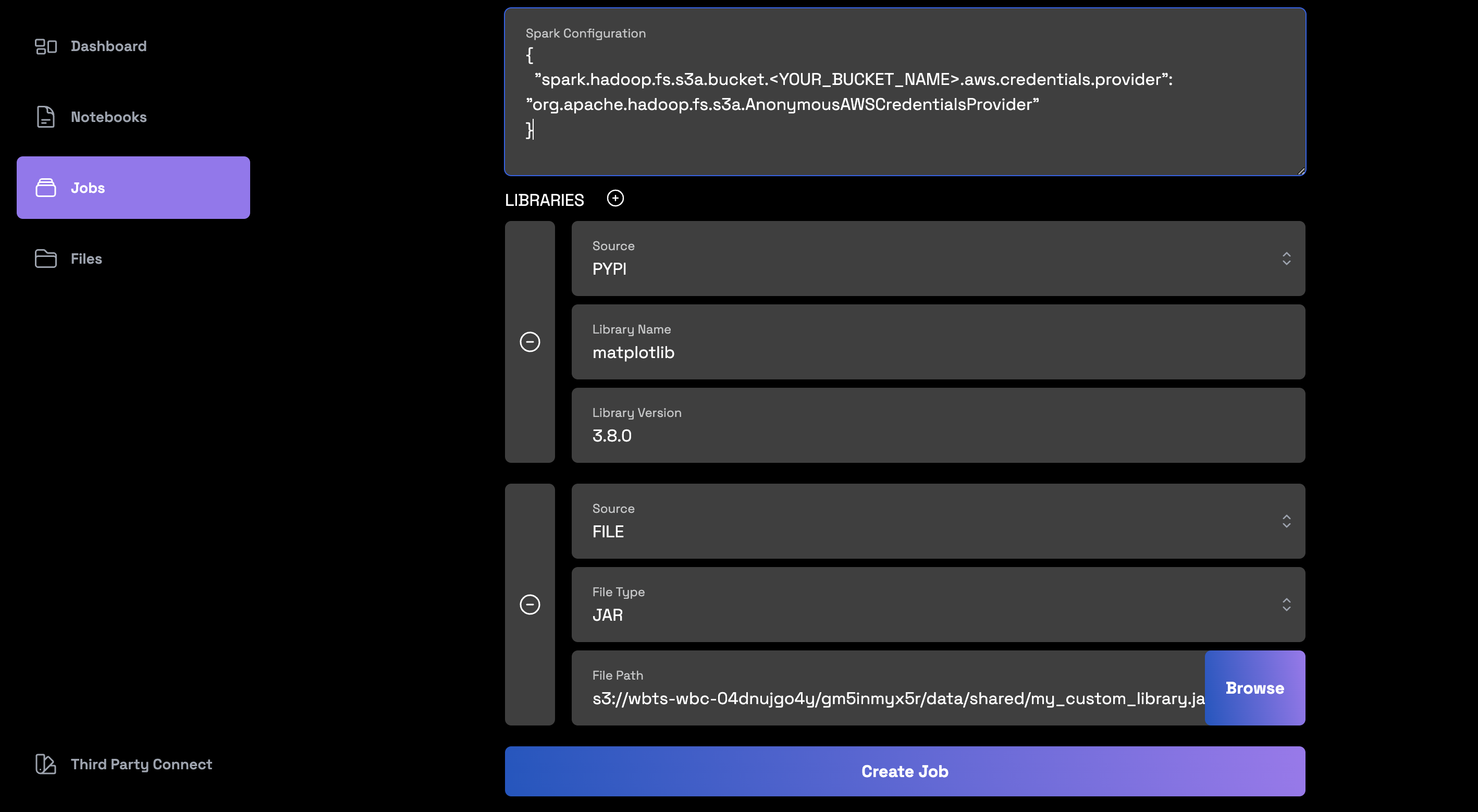
Configurations and Libraries¶
Spark Configuration¶
When creating a job, users have the option to specify Spark configurations. These configurations give users more granular control over Spark's behavior during job execution. Remember, these configurations need to be specified explicitly when creating a job.
Example for Accessing AWS S3 Buckets: To allow Spark to access and read files from an AWS S3 bucket, you can specify the AWS credentials provider in a JSON format:
{
"spark.hadoop.fs.s3a.bucket.<YOUR_BUCKET_NAME>.aws.credentials.provider": "org.apache.hadoop.fs.s3a.AnonymousAWSCredentialsProvider"
}
Replace <YOUR_BUCKET_NAME> with the name of your S3 bucket. This configuration uses the AnonymousAWSCredentialsProvider, which means no AWS credentials are required, so ensure your bucket permissions allow this type of access.
Working with Libraries¶
Wherobots supports adding external libraries to a job. These can be in the form of PyPi packages, wheel files, or JAR files.
-
PyPi: Simply specify the name of the package and its version. For example, to include the popular data manipulation library
pandas, you would add:- Library Name:
pandas - Library Version:
2.1.1
- Library Name:
-
Wheel Files & JAR Files:
- To include a specific library as a Wheel file or a JAR file, upload it directly using the browse function in the Libraries section.
- Example: If you have a custom library named
my_custom_library.jar, you can upload it directly. Similarly, for a Python Wheel file namedmy_python_lib.whl, use the same upload functionality. Ensure these files are accessible and compatible with your selected runtime.
-
Maven Libraries:
- Wherobots allows users to integrate libraries from Maven repositories directly into the Spark Configuration section.
- To add a Maven library, specify it in the Spark configuration using the
spark.jars.packagesproperty.
Example: To add Apache Commons Lang, you'd input into the Spark Configuration:
{
"spark.jars.packages": "org.apache.commons:commons-lang3:3.12.0"
}
File Paths and Directories¶
When adding files or scripts for your tasks, ensure that they are located in either the data/shared directory or the data/customer-<customer_id> directory. These directories are structured for organized data storage and efficient access.
Job Creation Confirmation¶
Upon defining the necessary configurations, users can confirm and create the job using the "Create Job" button.
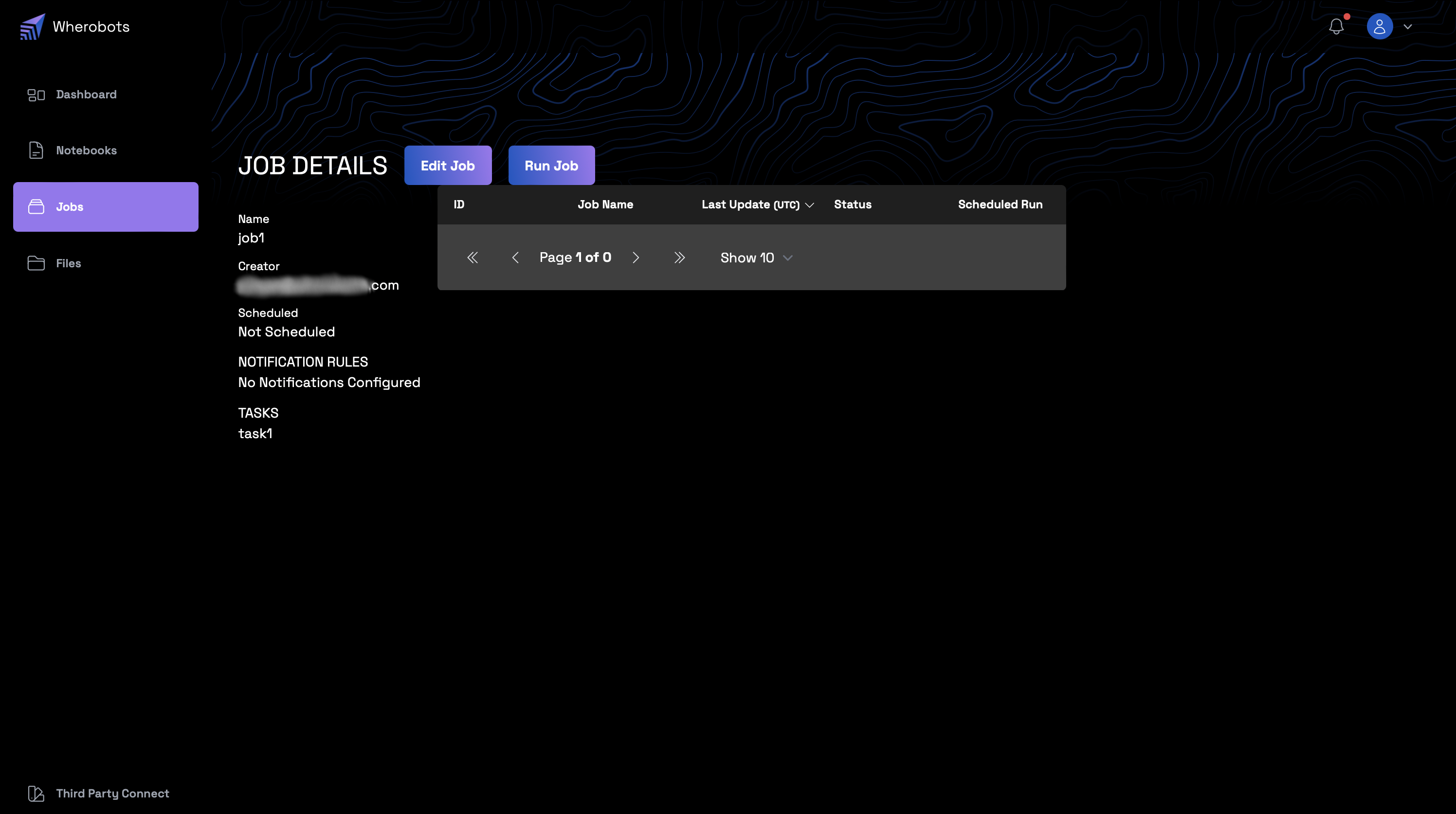
Job Execution¶
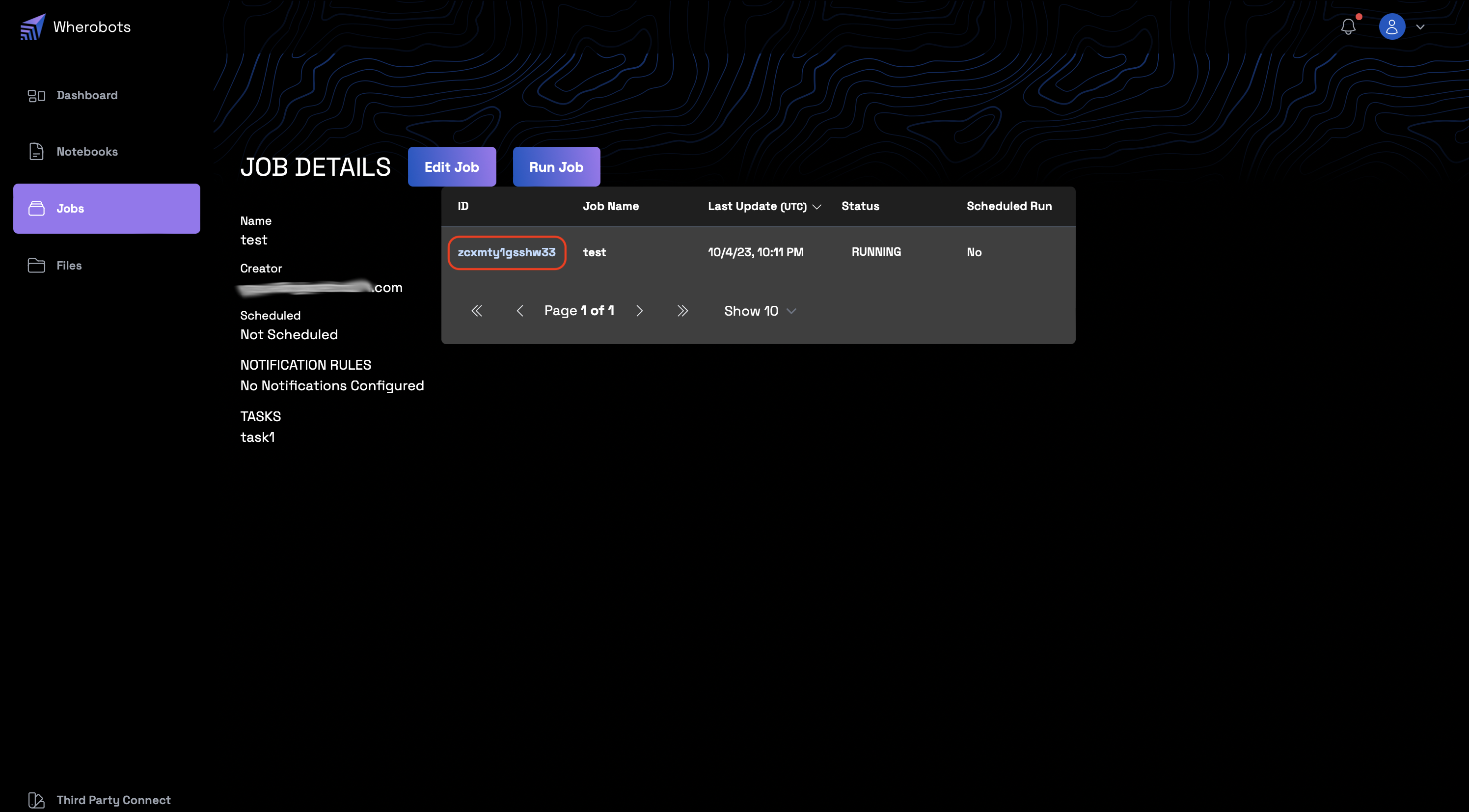
- Once a job is created, its details can be viewed from the "Job Details" page.
- The job can be executed by selecting the "Run Job" button.
Monitoring Job Progress¶
Accessing Job run output¶
- From the main "Jobs" dashboard, locate the specific job you wish to monitor.
- Click on the "Job ID" to access the detailed page of the job. This takes you to the "JOB RUN OUTPUT" section, offering a comprehensive view of the job's configuration and status.
Job Run Output¶
- This section captures the real-time output generated during the job's execution.
- Detailed logs, including timestamped messages and system-related outputs, offer insights into the job's operation.
- A "Wrap output" toggle is available for users to toggle between wrapped and unwrapped view of the output, optimizing readability based on preference.
- In case of any issues or errors during execution, detailed traces will be provided in this section, aiding in troubleshooting.
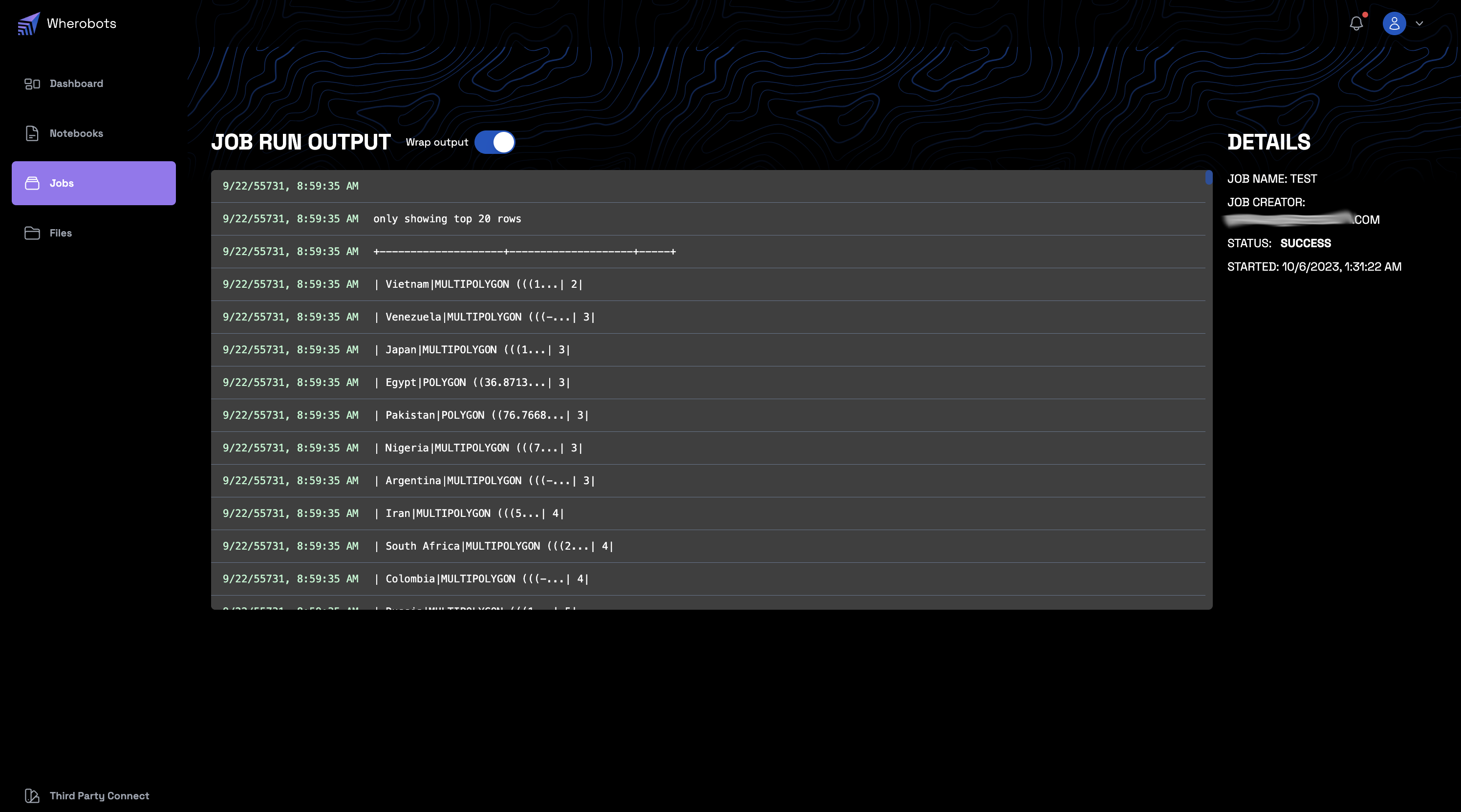
By monitoring the job details, users can gain a deep understanding of the job's operations, performance, and potential issues, ensuring efficient and optimized executions.
View System Events¶
- This section captures the system events generated during the job's execution.
- When you observe job failed or hanging with no log output, you can expand the tab to see if there is any message such as quota exceeded, etc.
