Introduction to Map Matching with Matcher
In GPS-based navigation systems, devices often provide GPS coordinates that might be imprecise and don’t necessarily align with actual road networks. This discrepancy can be addressed by a process known as map matching, which aligns these potentially inaccurate GPS points to their correct road segments, ensuring the accuracy of navigation routes and providing a seamless navigation experience for users.Import Matcher Functions
To leverage the map matching functionalities offered by Wherobots Matcher, you need to import the relevant class. The MapMatching class from the macher module provides these capabilities:- Python
- Scala
- Java
Loading OSM Data
Once you’ve accessed the MapMatching class, the next step is to load data from the OpenStreetMap (OSM). Wherobots Matcher supports loading an OSM file into a Sedona DataFrame. This DataFrame is then enriched with the necessary attributes for map matching. If your OSM data is saved at a local path like data/osm.xml, or on a remote storage such as an AWS S3 path, you can load this data using the following code:- Python
- Scala
- Java
[car] parameter is the road type filter, which can be used to filter out road segments that are not suitable for
cars.
Upon executing the above code, you can expect an output that aligns with the example below:
src(source): Represents the starting point or origin of a path. Each src has associated coordinates given by src_lat and src_lon.dst(destination): Refers to the endpoint of a path. Each dst has coordinates represented by dst_lat and dst_lon.
Create Sedona DataFrame of GPS Trips
With the Sedona library, which provides APIs and data structures for spatial operations, you can transform a list of GPS tracks into a Sedona DataFrame where each track is represented as a LineString. Follow these steps to create a Sedona DataFrame of GPS trips:- Format the given GPS coordinates into strings that can be converted into LineString objects.
- Next, Use Sedona’s API to create a DataFrame of these LineString objects.
- Python
- Scala
- Java
- Python
- Scala
- Java
Map Matching on Batch Data
Now that you have both the OSM edges DataFrame and the GPS trips DataFrame, you’re ready to perform map matching. The below code is used to execute map matching and display the top 5 rows of the resulting DataFrame.- Python
- Scala
- Java
match are as follows:
- dfEdge: A DataFrame of road segments from OpenStreetMap.
- dfPaths: A DataFrame of GPS paths to be aligned to roads.
- colEdgesGeom: The column in dfEdge holding road geometry.
- colPathsGeom: The column in dfPaths holding GPS path geometry.
- idFieldName: Optional - The column in dfPaths DataFrame that contains the unique identifier for each GPS trip. if not provided, the first non-geometry column is used.
Visualizing the result using SedonaKepler
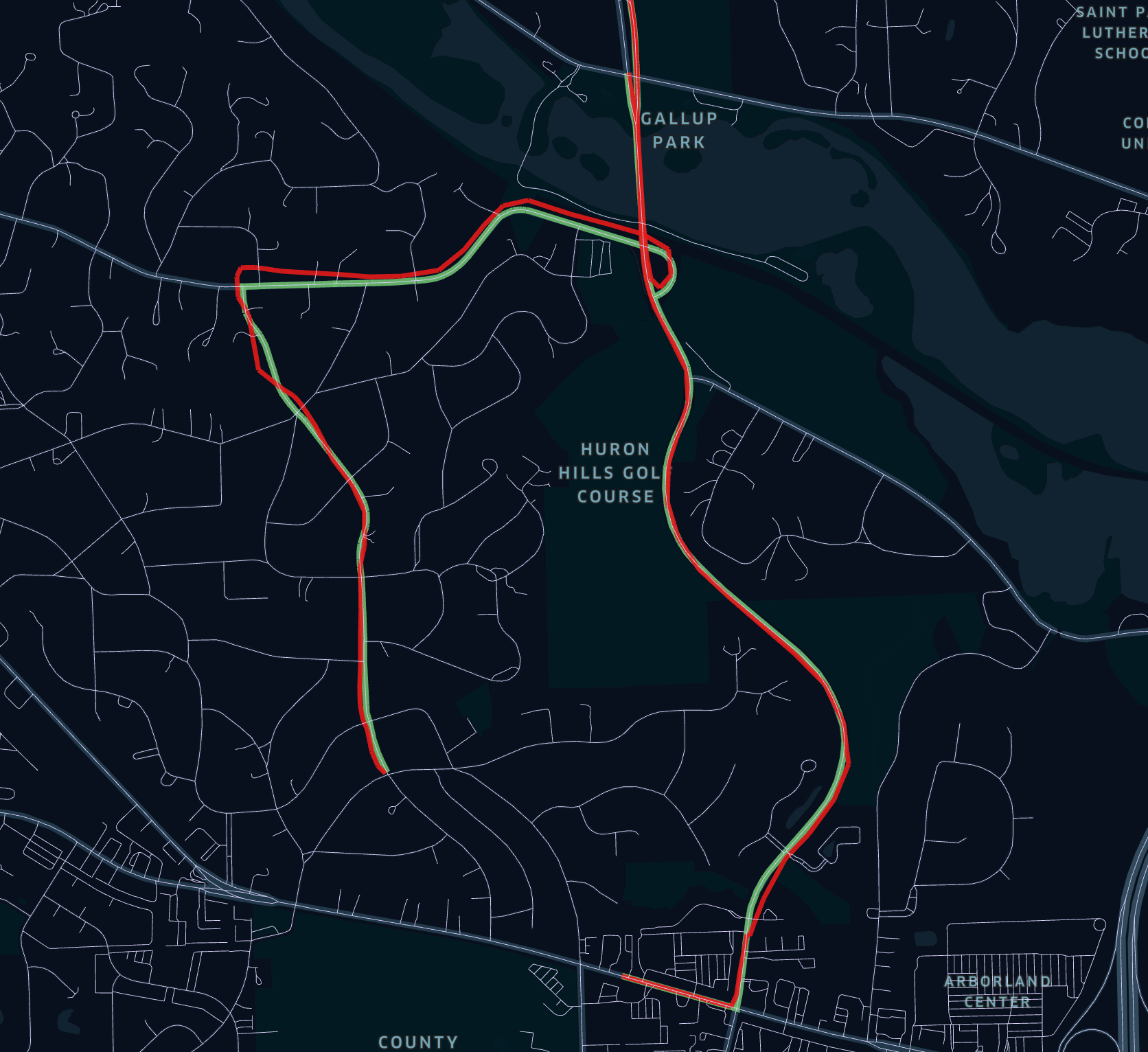
To visualize the map matching result using SedonaKepler, you can use the following code:- Red Line: Illustrates the raw GPS trajectories, which capture the vehicle’s original movement as recorded by the GPS device.
- Green Line: Highlights the trajectories after map matching, reflecting a refined path that aligns the GPS observations with the actual road network.
Advanced Configuration
Wherobots map matching has several advanced configs that can be set throughConfig:
- Python
- Scala
- Java
- Python
- Scala
- Java
Explanation
How Distributed Map-Matching Works
Wherobots runs batch map-matching on a large collection of trajectories in a distributed manner. The map-matching process is divided into two phases: distributing workloads and local map-matching. The distributing workloads phase rearranges the trajectories and the road segments near those trajectories to the same partition, and the local map-matching phase performs map-matching on each partition, where we already have trajectories and their surrounding road network co-located.Parameters for Distributing Map-Matching Workloads
- wherobots.tools.mm.numspatialpartitions
- Number of spatial partitions generated in the spatial join phase. This controls the parallelism of performing spatial join between trajectories and road networks. A recommended value is 10 * number of executor cores.
- Default value: None
- Possible values: any positive integer value
- Number of spatial partitions generated in the spatial join phase. This controls the parallelism of performing spatial join between trajectories and road networks. A recommended value is 10 * number of executor cores.
The Local Map-Matching Algorithm
The local map-matching algorithm is based on a Hidden Markov Model (HMM), which is popularized by the paper Hidden Markov Map Matching Through Noise and Sparseness. Wherobots implements a variation of this algorithm.Parameters for the Local Map-Matching Algorithm
- wherobots.tools.mm.matcher
- The algorithm for the local map matcher. The legacy mode works better for dense trajectories (high sampling rate) while the advanced mode works better for sparse trajectories (low sampling rate).
- Default value: legacy
- Possible values: legacy, advanced
- wherobots.tools.mm.adv.gpsaccuracy
- The GPS accuracy of the input data, in the unit of meters. This controls the search radius of each observation. For sparse data, a higher value (e.g., 40 meters) will improve the accuracy but decrease the speed.
- Default value: 20
- Possible values: any positive integer value
- wherobots.tools.mm.adv.partialmatch
- The local map matching algorithm will terminate early if it cannot find matches for every observation of a trip and the result will be a partial match of the original trip. This parameter controls if partial matches should be included in the output. If false, partial matches will become
LineString EMPTYin the final output DataFrame. - Defalue value: false
- Possible values: true, false
- The local map matching algorithm will terminate early if it cannot find matches for every observation of a trip and the result will be a partial match of the original trip. This parameter controls if partial matches should be included in the output. If false, partial matches will become